DeepSeek V4 - крупное обновление и что нового
-
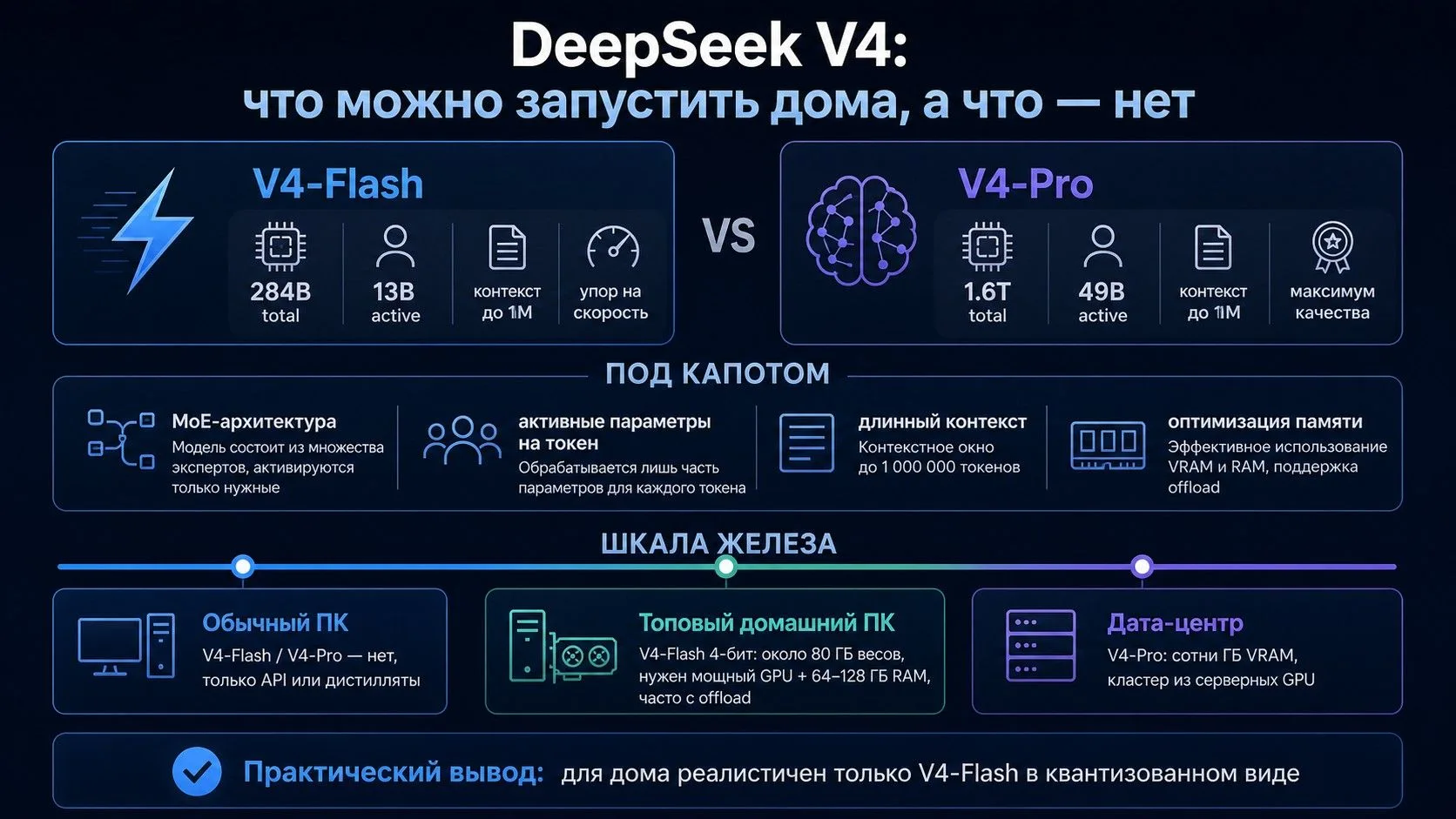
DeepSeek V4 - это не одна модель, а сразу две: V4‑Pro и V4‑Flash. Обе поддерживают до 1 миллиона токенов контекста, обе выложены как open‑weights под лицензией MIT, но на практике между ними огромная разница по требованиям к железу и по тому, насколько они вообще подходят для домашнего запуска.
Если говорить без маркетинга, то главный вопрос здесь не «насколько DeepSeek V4 умный», а «где это реально можно крутить». По официальному релизу и model card видно, что V4‑Pro - это флагман под тяжёлый reasoning, кодинг и agentic‑сценарии, а V4‑Flash - более компактный и быстрый вариант, который ближе к реальному использованию вне дата‑центра.
Что такое DeepSeek V4
DeepSeek V4 Preview был анонсирован как новая открытая линейка моделей с упором на длинный контекст и эффективность на agentic‑нагрузках. В официальном описании компания прямо разделяет семейство на DeepSeek‑V4‑Pro для максимального качества и DeepSeek‑V4‑Flash для скорости, цены и более лёгких сценариев.
С технической точки зрения обе модели относятся к классу MoE, то есть Mixture‑of‑Experts. Это означает, что общий размер модели очень большой, но на каждом токене активируется только часть параметров, поэтому реальные вычислительные затраты ниже, чем можно было бы ожидать по total‑числу параметров.
Для пользователя это важно по двум причинам. Во‑первых, large‑scale MoE позволяет сочетать высокий уровень качества с более разумной стоимостью инференса. Во‑вторых, даже при этом размер моделей остаётся настолько большим, что локальный запуск без компромиссов быстро упирается в память и пропускную способность системы.
Кстати не раз уже говорил, что пользуюсь агрегатором polza.ai там как раз можно пощупать саму модельку или поработать с ней через Api
Чем отличаются V4‑Pro и V4‑Flash
По официальным спецификациям DeepSeek‑V4‑Pro имеет 1.6T total параметров и 49B active параметров, а DeepSeek‑V4‑Flash - 284B total и 13B active параметров (Это реально дохрена). При этом обе модели поддерживают контекст длиной до 1M токенов и доступны через API, а также как открытые веса для самостоятельного развертывания.
Практически разница такая:
Параметр V4‑Flash V4‑Pro Total parameters 284B 1.6T Active parameters 13B 49B Контекст До 1M токенов До 1M токенов Основной сценарий Быстрый inference, чат, суммаризация, routing Сложный reasoning, код, long‑context agents Реалистичность локального запуска Частично возможен с компромиссами Практически только серверная/кластерная среда V4‑Flash - это модель, которую можно рассматривать как базу для личного ассистента, RAG‑помощника, локального чат‑интерфейса или быстрого инженерного copilot‑сценария. V4‑Pro - это уже история про максимальное качество, тяжелые многошаговые задачи, агентные пайплайны и инфраструктуру, которая стоит далеко за пределами обычного домашнего ПК.
Что у них под капотом
Официальные материалы подчеркивают, что ключевой акцент в V4 сделан не только на размере модели, но и на эффективности длинного контекста. В архитектуре используются Compressed Sparse Attention и Heavily Compressed Attention, а в релизе DeepSeek это описано как token‑wise compression и DSA для снижения вычислительных и memory‑затрат на длинных окнах контекста.
По model card, в режиме 1M токенов DeepSeek‑V4‑Pro требует только 27% single‑token inference FLOPs и 10% KV cache по сравнению с DeepSeek‑V3.2. Это очень важный момент: при работе с длинным контекстом узким местом становится не только сам размер весов, но и объём KV‑кэша, поэтому любые оптимизации внимания напрямую влияют на реальную возможность обслуживать большие диалоги, документы, логи и цепочки agent‑вызовов.
Кстати я сам фиксил многие вещи уже через DeepSeek V4-flash в связке с редактором ZED - и это просто потрясающе!
Ещё одна важная деталь - режимы reasoning. И V4‑Pro, и V4‑Flash поддерживают три режима: Non‑think, Think High и Think Max. Это означает, что одну и ту же модель можно использовать как в быстром ежедневном режиме, так и в более «тяжёлом» режиме рассуждений, когда важнее качество ответа, чем скорость.
На практике это особенно интересно для личного ассистента. В обычном режиме модель может быстро отвечать на рутинные вопросы, а в Think High или Think Max - разбирать код, планировать действия, раскладывать задачу по шагам и работать как более обстоятельный агент.
Ну и если отвечать коротко потянет ли домашний пк эти модельки:
- Обычный ноутбук или ПК - только API, облачный доступ или небольшие производные модели/дистилляты.
- Топовый домашний ПК - потенциально V4‑Flash в квантизованном виде, но с большим объемом RAM и частичным offload.
- Серверная или кластерная среда - V4‑Pro и полноценные long‑context конфигурации.
Коротко о главном
DeepSeek V4 - это одна модель или две?
Это семейство из двух моделей: DeepSeek‑V4‑Pro и DeepSeek‑V4‑Flash.У обеих моделей действительно 1M контекст?
Да, и в официальном релизе, и в model card для обеих моделей указан контекст до 1 миллиона токенов.Чем Pro отличается от Flash на практике?
Pro ориентирован на максимальное качество, сложный reasoning и agentic‑нагрузки, а Flash - на более быстрый и экономичный inference.Можно ли поставить DeepSeek V4 на домашний компьютер?
V4‑Flash теоретически можно запускать локально в квантизованном виде на очень мощном ПК, а V4‑Pro практически относится к серверному классу развёртывания.Подходит ли V4‑Flash для личного ассистента?
Да, это более реалистичный вариант, чем Pro, если нужен локальный или полу‑локальный ассистент с упором на скорость и разумные требования к инфраструктуре. (Кстати с последними версиями OpenClaw flash версия deepseek стала по умолчанию)Какие режимы работы есть у моделей?
Обе модели поддерживают Non‑think, Think High и Think Max.Подходят ли эти модели для кода и агентных задач?
Да, DeepSeek отдельно продвигает V4 как линейку для coding, long‑context agents, document analysis и tool‑calling сценариев.
Здравствуйте! Похоже, вас заинтересовала эта беседа, но у вас ещё нет аккаунта.
Надоело каждый раз пролистывать одни и те же посты? Зарегистрировав аккаунт, вы всегда будете возвращаться на ту же страницу, где были раньше, и сможете выбирать, получать ли уведомления о новых ответах (по электронной почте или в виде push-уведомлений). Вы также сможете сохранять закладки и ставить лайки постам, чтобы выразить свою благодарность другим участникам сообщества.
С вашими комментариями этот пост мог бы стать ещё лучше 💗
Зарегистрироваться Войти© 2024 - 2026 ExLends, Inc. Все права защищены.